|
|
It is not essential to use lex
to handle problems of this kind: you could
write programs in a standard language
like C to handle them.
What lex does is generate such C programs, based on a set of
specifications that you give it.
These lex specifications name and
describe the classes of strings that you wish to recognize, and
often give actions to be carried out when a particular kind of
string is found.
lex is referred to as a ``program generator'': more
specifically, it is a ``lexical analyzer generator''.
It offers a faster,
easier way to create programs to perform lexical analysis.
Its weakness is that it often produces C programs that are longer
and execute more slowly than hand-coded programs that
do the same task.
In many applications size and speed are minor considerations,
and the advantages of using lex considerably outweigh
these disadvantages.
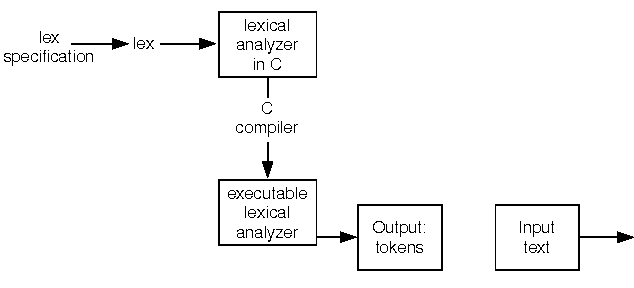
To understand what lex does, refer to ``Creation and use of a lexical analyzer with lex''. It begins with a lex specification, sometimes referred to as a lex source program. The source is read by the lex program generator. The output of the program generator is a C program which, in turn, must be compiled in order to generate an executable program that performs the lexical analysis. The lexical analyzer program produced by this process accepts as input any source file and produces the specified output, such as altered text or a list of tokens.
Creation and use of a lexical analyzer with lex
Programs generated by lex can also be used to collect statistical data on features of the input, such as character count, word length, and the number of occurrences of particular words. In later sections of this chapter, you will see how to:
This chapter is organized as follows: